|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 |
<%@LANGUAGE="VBSCRIPT" CODEPAGE="936"%> <% 'codepage=936简体中文 'codepage=950繁体中文 'codepage=65001UTF-8 url="http://www.gkj.com.cn/article.asp?id=21" 'url=request.Form("weburl") 'num=request.Form("count") 'str=GetBody(url) 'start="<div id=""logPanel"" class=""Content-body"">" 'ends="</div>" 'response.Write body(str,start,ends) Hello("http://list.mp3.baidu.com/song/A.htm" , "<table width=""90%"" border=""0"" align=""center"" cellpadding=""3"" cellspacing=""0"" bgcolor=""#f5f5f5"" >" , "<div align=center>" , ".*(<td width=""20%""><a href="".*\.htm"" target=_blank>)(.*)(</a></td>)[.\n]*", "<font style=""font-size:9pt;"" color=blue>$2</font>") %> <form action="" method="post"> 采集网址 <input type="text" size="100" name="weburl"> 采集数量 <input type="text" size="5" name="count"> <input type="submit" value="submit"> </form> <% '1、取得网站的分页列表页的每页地址 '2、获取被采集网站的分页列表页内容 '3、从分页列表代码中提取被采集的内容页面的URL连接地址 '4、取得被采集的内容页面内容 '用以下代码就可以获得一个URL连接集合 '以下内容为程序代码: 'Set xiaoqi = New Regexp 'xiaoqi.IgnoreCase = True 'xiaoqi.Global = True 'xiaoqi.Pattern = """.+?""" 'Set Matches =xiaoqi.Execute(页面列表内容) 'set xiaoqi=nothing 'url="" 'For Each Match in Matches 'url=url&Match.Value 'Next '用serverXMLHTTP组件获取数据 '调用方法:GetBodyServer(文件的URLf地址) Function GetBodyServer(weburl) '创建对象 Dim ObjXMLHTTP Set ObjXMLHTTP=Server.CreateObject("MSXML2.serverXMLHTTP") '请求文件,以异步形式 ObjXMLHTTP.Open "GET",weburl,False ObjXMLHTTP.send While ObjXMLHTTP.readyState <> 4 ObjXMLHTTP.waitForResponse 1000 Wend '得到结果 GetBodyServer=ObjXMLHTTP.responseBody '释放对象 Set ObjXMLHTTP=Nothing End Function 'XMLHTTP组件获取数据 '调用方法:GetBody(文件的URLf地址) Function GetBody(weburl) '创建对象 Set Retrieval = CreateObject("Microsoft.XMLHTTP") With Retrieval .Open "Get", weburl, False, "", "" .Send GetBody =BytesToBstr( .ResponseBody , "GB2312") End With '释放对象 Set Retrieval = Nothing End Function 'BytesToBstr(要转换的数据,编码) '编码常用为GB2312和UTF-8 Function BytesToBstr(body,Cset) dim objstream set objstream = Server.CreateObject("adodb.stream") objstream.Type = 1 objstream.Mode =3 objstream.Open objstream.Write body objstream.Position = 0 objstream.Type = 2 objstream.Charset = Cset BytesToBstr = objstream.ReadText objstream.Close set objstream = nothing End Function '后期处理 Function Hello(strUrl, strStart, strEnd, patrn, replStr) Str = GetBody(strUrl) Str = MyMid(Str, strStart, strEnd) Str = ReplaceTest(patrn, replStr, Str) Hello = Str End Function Function MyMid(Str, strstart, strend) If strstart = "" Then i = 0 Else i = InStr(Str, strstart) End If If strend = "" Then j = Len(Str) Else j = InStr(i, Str, strend) End If MyMid = Mid(Str, i, j - i + 1) End Function Function ReplaceTest(patrn, replStr, str1) Dim regEx, match, matches Set regEx = New RegExp regEx.Pattern = patrn regEx.IgnoreCase = True regEx.Global = True Set matches = regEx.Execute(str1) For Each match in matches ReplaceTest = ReplaceTest@Ex.Replace(Match.Value, replStr) Next End Function '用ASP内置的MID函数截取需要的数据 '调用方法:body(被采集的页面的内容,开始标记,结束标记) Function bodyb(wstr,start,over) start=Newstring(wstr,start) '设置需要处理的数据的唯一的开始标记 over=Newstring(wstr,over) '和start相对应的就是需要处理的数据的唯一的结束标记 body=mid(wstr,start,over-start) '设置显示页面的范围 End Function '用正则获取需要的数据 '调用方法:body(被采集的页面的内容,开始标记,结束标记) Function body(wstr,start,over) Set xiaoqi = New Regexp '设置配置对象 xiaoqi.IgnoreCase = True '忽略大小写 xiaoqi.Global = True '设置为全文搜索 xiaoqi.Pattern = ""&start&".*?"&over&"" '正则表达式 Set Matches =xiaoqi.Execute(wstr) '开始执行配置 set xiaoqi=nothing body="" For Each Match in Matches body=body&Match.Value '循环匹配 Next End Function %> |
不因成就而狂妄、不因失落而气馁、不因欲望而沉重、不因嫉妒而困扰
-
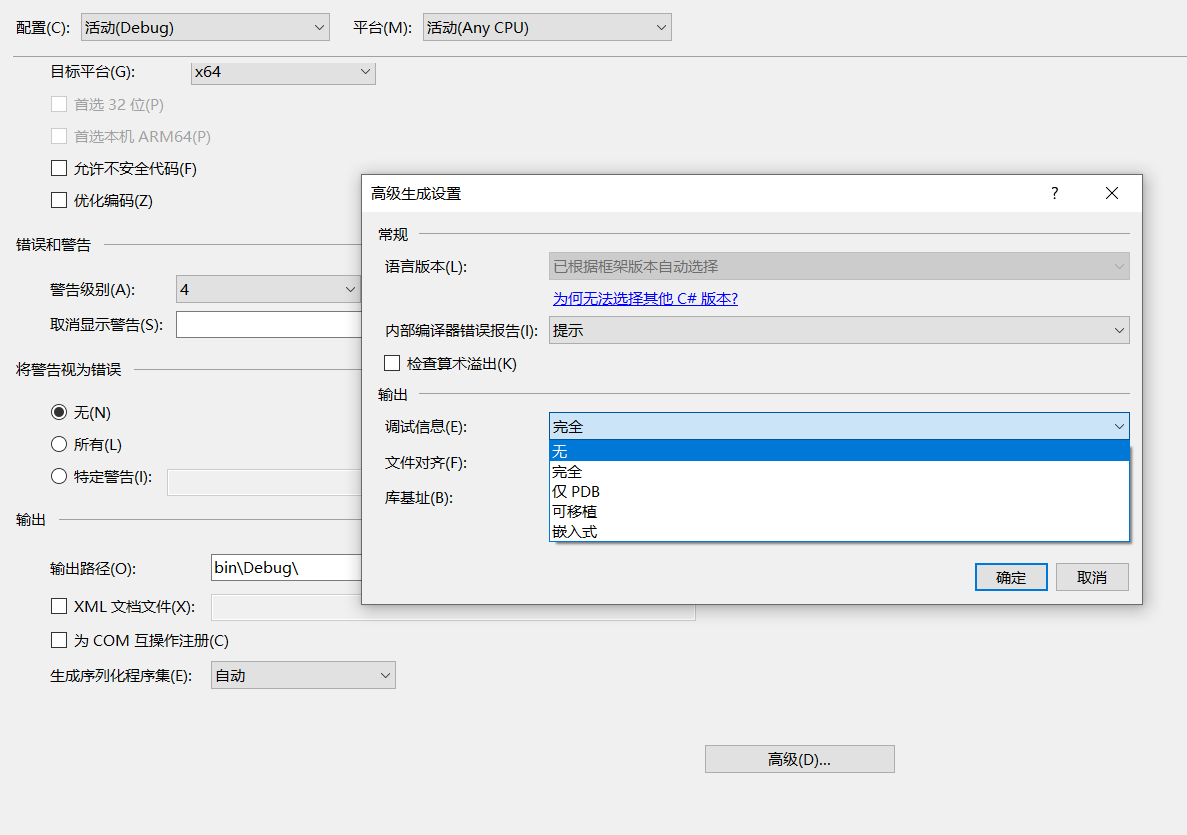 ASP.NET让引用的dll不生成.pdb 2025年6月26日
ASP.NET让引用的dll不生成.pdb 2025年6月26日 -
crontab的注意事项 2024年10月22日
-
小米路由MINI(R1C)刷 OpenWrt 2024年8月27日
-
OpenWRT 扩展容量 2024年6月17日